
Kubernetes for Data Science: meet Kubeflow

Rui Vasconcelos
on 26 May 2020
Tags: AI , Cloud Native , deep learning , Kubeflow , kubernetes , ML , MLOps
Deep Learning is set to thrive
Data science has exploded as a practice in the past decade and has become an undisputed driver of innovation.
The forcing factors behind the rising interest in Machine Learning, a not so new concept, have consolidated and created an unparalleled capacity for Deep Learning, a subset of Artificial Neural Networks with many hidden layers, to thrive in the years to come.
Deep Learning enabling factors:
- Computational capacity: increased exponentially (GPGPUs and TPUs)
- Hardware availability: at low cost (Public & hybrid Clouds, efficient data centres)
- Data availability: publicly accessible data, low-cost widespread IoT devices
- Open source community: Libraries – TensorFlow, PyTorch; Competitions – Kaggle
But it still faces many challenges
The common pathway for a data scientist is to start by writing a model on a Jupyter notebook using Python and amazing open source libraries such as TensorFlow, Keras or PyTorch. When starting out, we tend to be focused on the end result of the model, but, there is a lot more.
While trying to bring the model to the hands of users or to edge devices, things get more complicated. In fact, developing the model itself is only a fairly small portion of the effort required to train, deploy and manage an AI project.
There is just a lot of background work to be done:
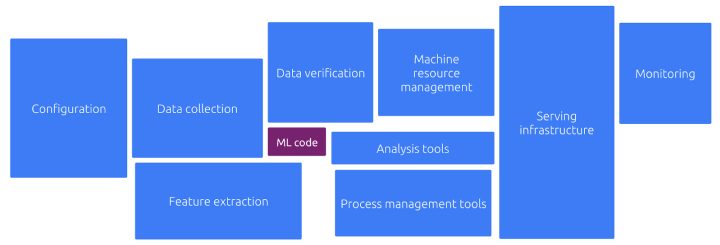
The typical Machine Learning workflow can look like this:

With these different stages, having diverse requirements, the challenges that arise are threefold:
- Composability – The workflow from data ingestion to model serving, monitoring and logging, includes many components spread across multiple systems making it hard to manage, secure and maintain.
- Portability – At different stages of the ML process, computation requirements change, and so does the hardware in which your software is running – Laptop, on-prem training rig, public cloud.
- Scalability – Computation requirements for AI projects are very dynamic, a training phase is resource intensive, while the inference phase is lightweight and speedy, hence, having elasticity at the infrastructure level is compulsory.
The word that best defines these needs is MLOps.

Kubernetes can help
Kubernetes (a.k.a. K8s) is an open source system to automate deployment, scaling, and management of containerized applications widely used in the world of DevOps.
For Data Scientists with the above mentioned challenges, this means they can package each step of the process as a container, making it system agnostic (portable) and composable (i.e. modular building blocks), and have Kubernetes handle the deployment and management at scale.
However, why not simply use the great powers of Kubernetes?
The only problem is, we need to become experts in:
– Kubernetes service endpoints
– Immutable deployments
– Persistent volumes
– GPGPU passthrough
– Drivers & the GPL
– Containers
– Cloud APIs
– Packaging
– DevOps
– Scaling
– (…)

Meet Kubeflow
Kubeflow makes deployments of Machine Learning workflows on Kubernetes simple, portable and scalable.
Kubeflow is the machine learning toolkit for Kubernetes. It extends Kubernetes ability to run independent and configurable steps, with machine learning specific frameworks and libraries.
And, it is all open source!
Run it on your workstation, on-premises training rig, or in any hybrid or public cloud, in a new or already running Kubernetes deployment. Within Kubeflow you will find all the open source tools and frameworks you need:

- Jupyter Notebooks
- Frameworks for Training: PyTorch, TensorFlow, Chainer, MPI, MXNet
- Hyperparameter tuning: Katib
- Serving: KFServing, Seldon Core, BentoML, Nvidia Triton, TensorFlow Serving
- Multi-Tenancy: Multi-user isolation and Identity Access Management (IAM)
To know more, visit ubuntu.com/kubeflow, or install Kubeflow by following the tutorial Deploy Kubeflow on Ubuntu, Windows and MacOS.
In upcoming posts, we will dive deeper into the technologies that make Kubeflow, and how you can leverage them to enhance your Data Science capabilities. Subscribe to our Cloud and Server newsletter to stay up to date.
Run Kubeflow anywhere, easily
With Charmed Kubeflow, deployment and operations of Kubeflow are easy for any scenario.
Charmed Kubeflow is a collection of Python operators that define integration of the apps inside Kubeflow, like
katib or pipelines-ui.
Use Kubeflow on-prem, desktop, edge, public cloud and multi-cloud.
What is Kubeflow?
Kubeflow makes deployments of Machine Learning workflows on Kubernetes simple, portable and scalable.
Kubeflow is the machine learning toolkit for Kubernetes. It extends Kubernetes ability to run independent and
configurable steps, with machine learning specific frameworks and libraries.
Install Kubeflow
The Kubeflow project is dedicated to making deployments of machine learning workflows on Kubernetes simple,
portable and scalable.
You can install Kubeflow on your workstation, local server or public cloud VM. It is easy to install
with MicroK8s on any of these environments and can be scaled to high-availability.
Newsletter signup
Related posts
Let’s talk about open source, AI and cloud infrastructure at GITEX 2024
October 14 – 18, 2024. Dubai. Hall 26, Booth C40 The largest tech event of the world – GITEX 2024 – is taking place in Dubai next week. This event is a great...
How to deploy AI workloads at the edge using open source solutions
Running AI workloads at the edge with Canonical and Lenovo AI is driving a new wave of opportunities in all kinds of edge settings—from predictive maintenance...
Charmed Kubeflow 1.9 Beta is here: try it out
After releasing a new version of Ubuntu every six months for 20 years, it’s safe to say that we like keeping our traditions. Another of those traditions is...